Fine-Tuning
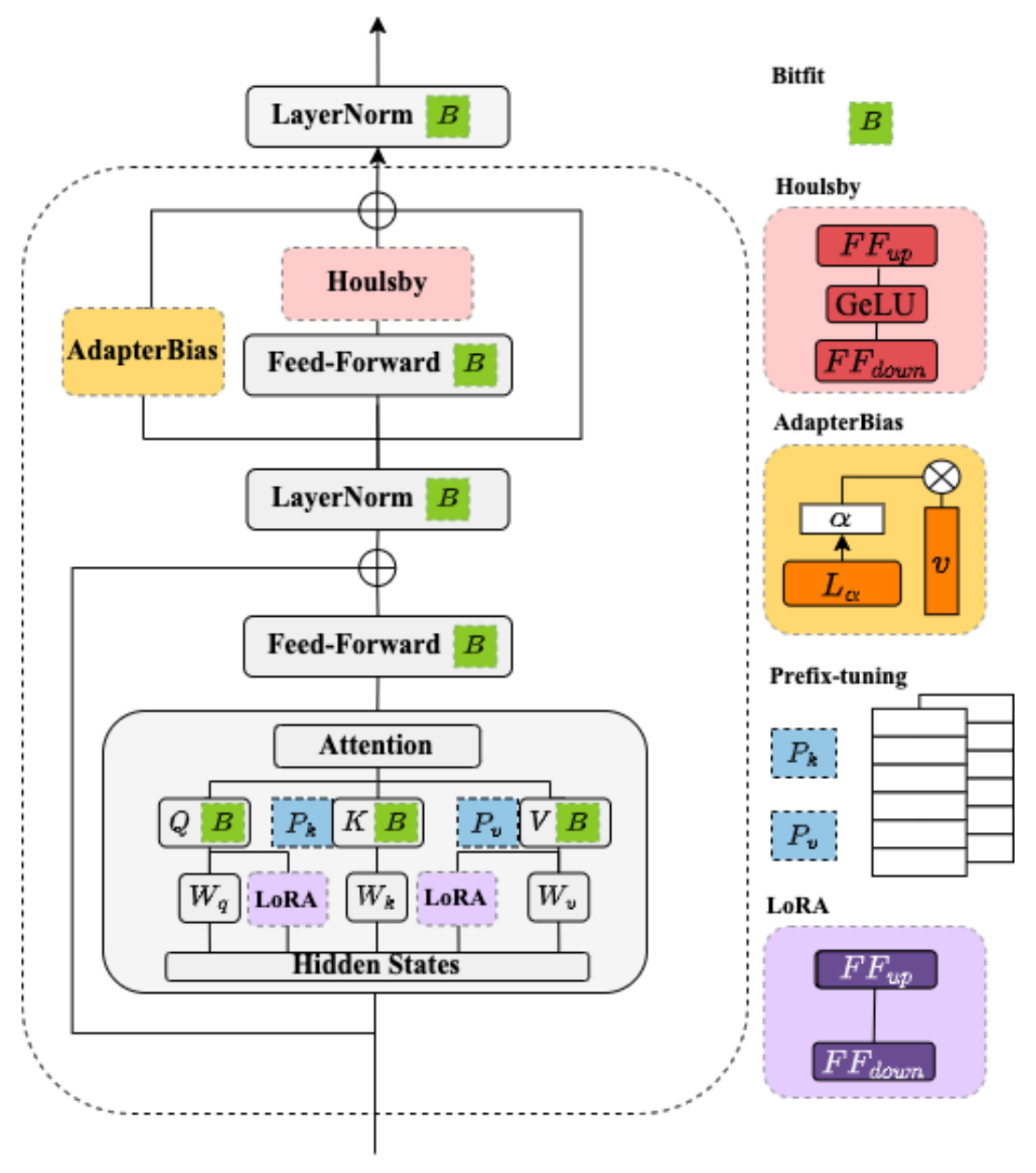
BERT Adapters
Supervised Fine-Tuning
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
trainer = SFTTrainer(
model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()
Instruction-Tuning
Make model can understand human instructions not appear in training data:
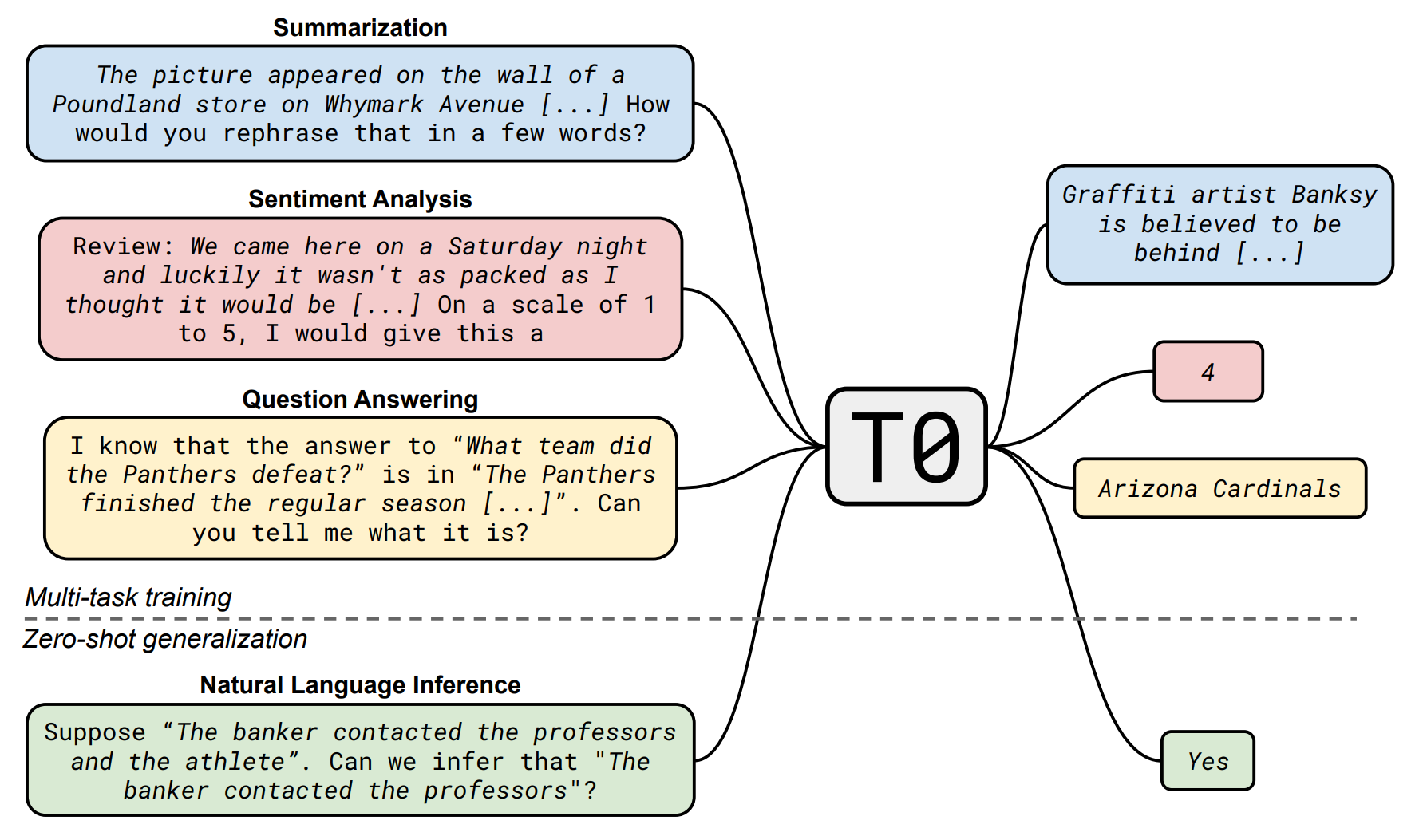
- 提高指令复杂性和多样性能够促进模型性能的提升.
- 更大的参数规模有助于提升模型的指令遵循能力.
Low-Rank Adaptation
低秩适配 (LoRA) 是一种参数高效微调技术 (Parameter-efficient Fine-tuning), 其基本思想是冻结原始矩阵 , 通过低秩分解矩阵 和 来近似参数更新矩阵 , 其中 是减小后的秩:
在微调期间, 原始的矩阵参数 不会被更新, 低秩分解矩阵 和 则是可训练参数用于适配下游任务. LoRA 微调在保证模型效果的同时, 能够显著降低模型训练的成本.